


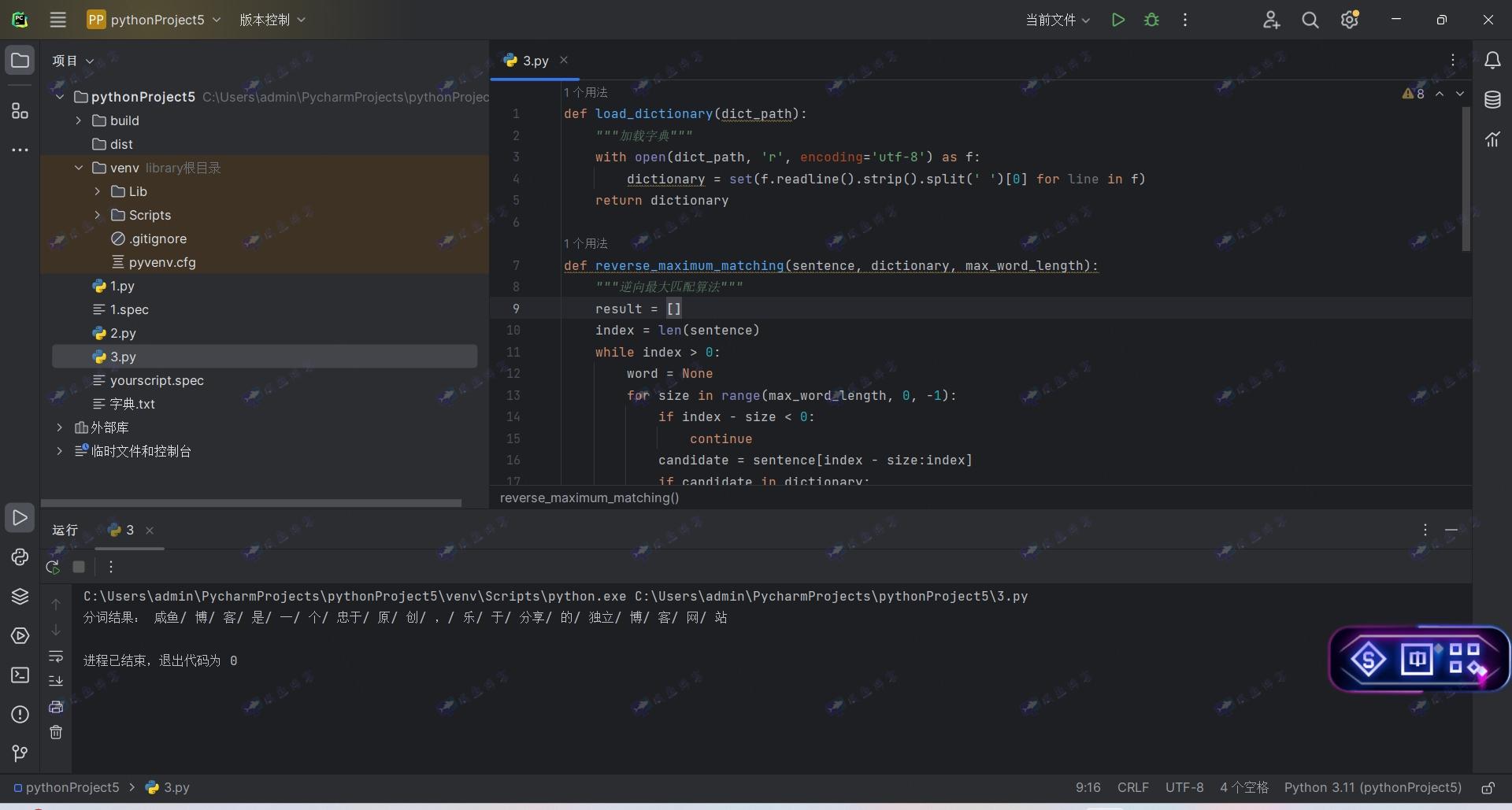
逆向最大匹配算法是一种分词方法,它从待分词语句的末尾开始匹配,每次匹配最长的词语。其算法核心思想是从指定的字典文件中加载词汇,并对给定的句子进行分词处理。以下给出一个python代码示例
def load_dictionary(dict_path):
"""加载字典"""
with open(dict_path, 'r', encoding='utf-8') as f:
dictionary = set(f.readline().strip().split(' ')[0] for line in f)
return dictionary
def reverse_maximum_matching(sentence, dictionary, max_word_length):
"""逆向最大匹配算法"""
result = []
index = len(sentence)
while index > 0:
word = None
for size in range(max_word_length, 0, -1):
if index - size < 0:
continue
candidate = sentence[index - size:index]
if candidate in dictionary:
word = candidate
result.append(word)
index -= size
break
if word is None:
index -= 1
result.append(sentence[index])
result.reverse()
return result
if __name__ == "__main__":
# 指定字典文件路径
dict_path = r"C:\Users\admin\PycharmProjects\pythonProject5\字典.txt"
# 加载字典
dictionary = load_dictionary(dict_path)
# 待分词句子
sentence = "咸鱼博客是一个忠于原创,乐于分享的独立博客网站"
# 假设最长词语长度为5
max_word_length = 5
# 进行分词
segmented_sentence = reverse_maximum_matching(sentence, dictionary, max_word_length)
# 输出分词结果
print("分词结果:", "/ ".join(segmented_sentence))
运行结果













这一切,似未曾拥有